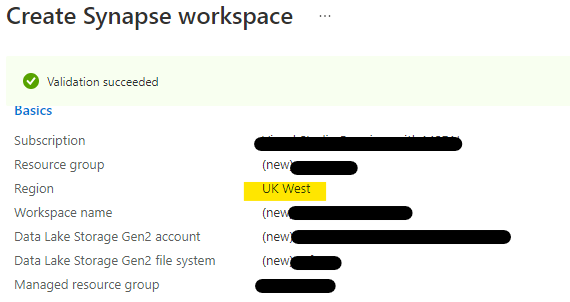
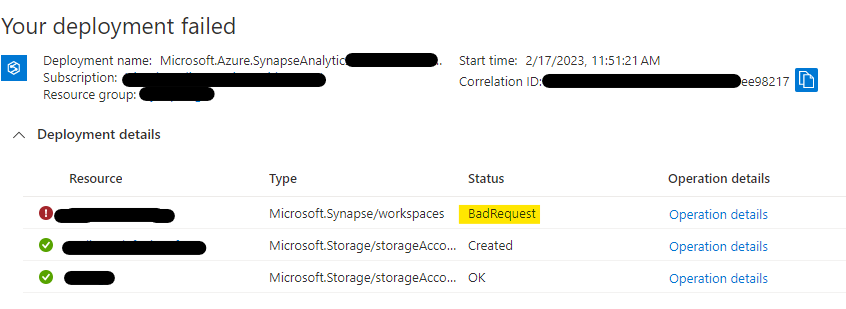
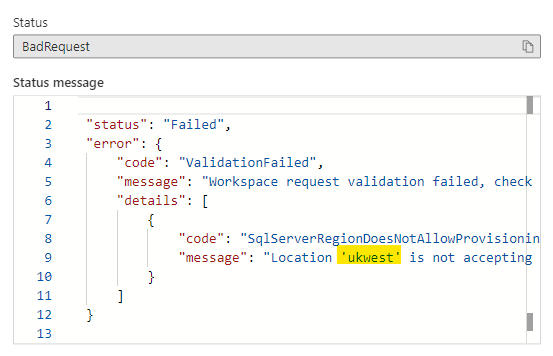
Like some people, I really love/hate the fact that things in the Azure Portal change.
It’s great to see new functionality being added to make things easier (love), but it means that you have to keep going back and updating previous content (hate), and all the stuff you learned you now have to re-learn (hate). On the plus side though, going back to Azure after a while and finding something new and fun – that’s a LOVELOVELOVE from me !
Having taken a break for reasons I won’t go into rn, recently someone asked me about Synapse Analytics using CSVs or Parquet files in Data Lake Storage Gen2, and crafting queries and notebooks in a Synapse Workspace.
Naturally, you start with the OPENROWSET() feature and point your queries directly at the files, but this gets quite cumbersome with complex queries from multiple sources. It would be far easier to just use them like database tables – you know, old skool stylee.
Again, quite naturally from that you start to look into Create External Table As Select (CETAS) and all the syntactic joy and heartache that CETAS can bring. Seriously, why isn’t there an easy way to do this ??
Well….
…there is !😊
What follows is me getting rabbit-holed by stuff (easy, amirite?), and assumes that you’ve already linked the Bing COVID-19 sample dataset to your workspace:

* If you’ve also linked your ADLSGen2, you can do this from there as well, but let’s stick with something that’s easily reproduceable.
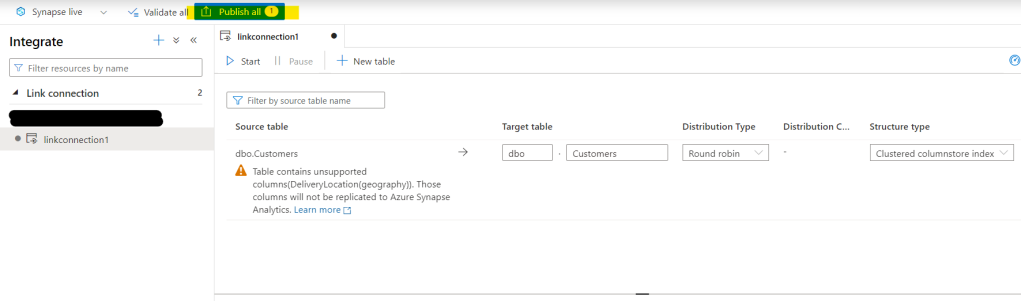
A quick click on the ellipsis shows you ‘New SQL Script’, and following the arrow shows you… Create External Table (tadaaaa):
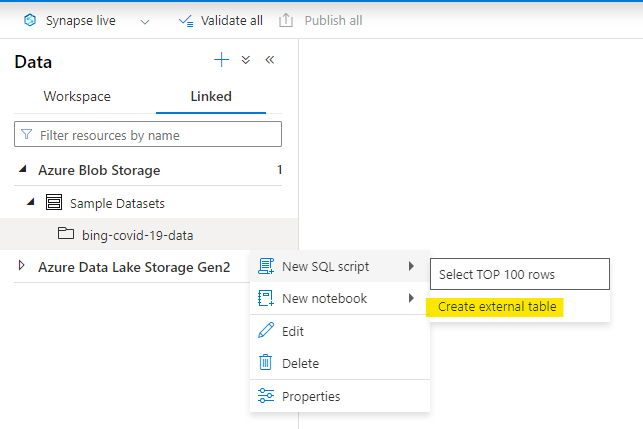
Happy-happy-joy-joy ! A thing to decomplexitate the complex thing !!
Right, let’s go… we’re gonna CETAS LIKE A BOSS !
A blade opens up on the right hand side…
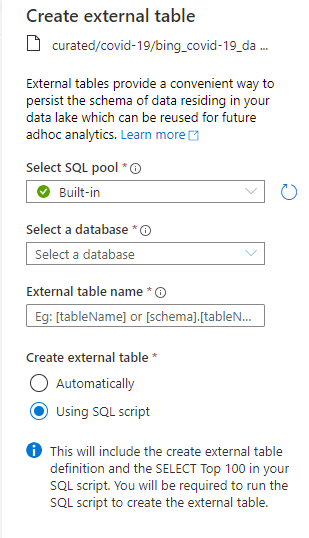
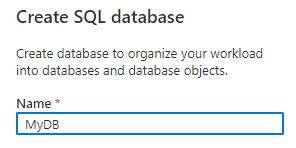
OK, so it wants to use the built-in serverless pool. That’s awesome – something else I don’t have to think about. Oh, but it wants a database to create the table in, and I don’t actually have any SQL Database at the moment, so let’s create a new one from the dropdown…
Once that’s done, we can then select it in the dropdown. We need to give the resulting table a schema and a name (I lazily typed [dbo].[SampleData] because I’m not that creative), and there’s a couple of interesting radio buttons after that – one to J*DI and give me a script to just show the first hundred rows from my new external table, and one to show me a script that does all the work, and *then* show the first hundred rows. Being an impetuous type, I J want to *ing D I, so I selected the automatic option.
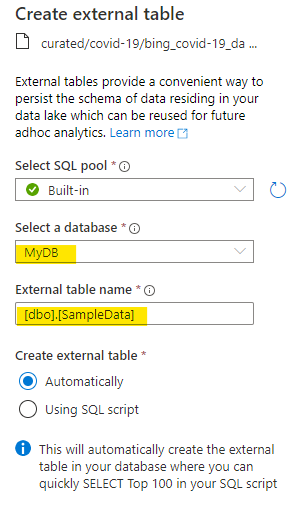
*if you’re into scripting or want to re-use the code elsewhere, feel free to use the other option. It’s not massively interesting at this point is all I’m saying.
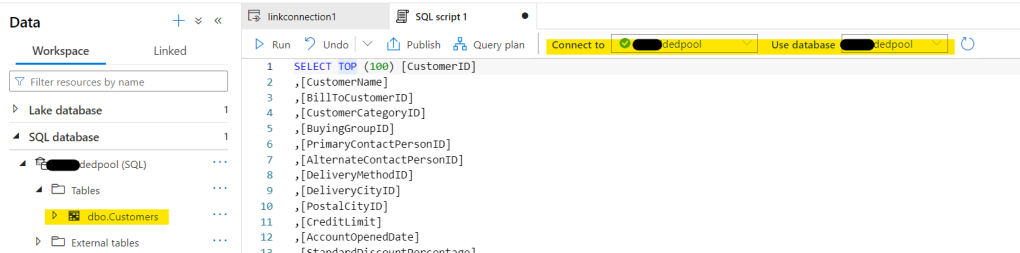
Boom ! We have a script for the first hundred rows, and when we run it, we get… 100 rows !
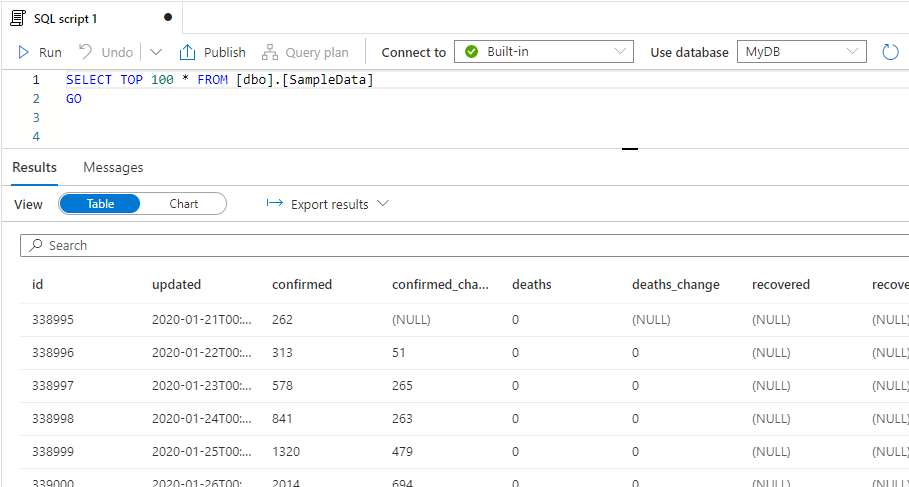
Awesome ! I can see that it’s using my new database ‘MyDB’ as well. Imma just gonna head over to the Workspace page and look at my new database 🤩..
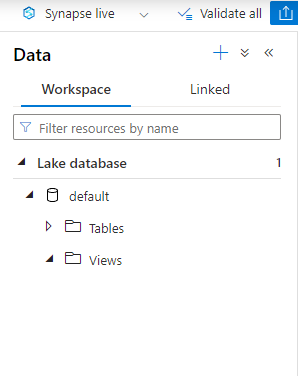
Where’s my new database ? I’ve got a Lake Database, sure, but I should see a SQL Database here by now ? Time for a coffee.
………………
I’m back ! Sorry, had to have a chocolate Hob Nob as well. Hmm, I don’t want to lose my open script, but there’s nowhere to refresh *just* the workspace pane..
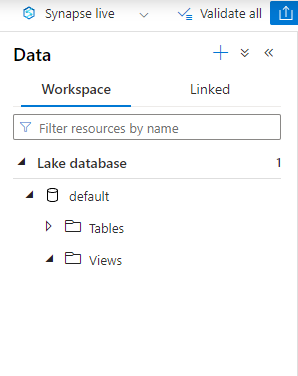
Refreshing the whole page will add the node for SQL Databases (but you’ll lose any unsaved/unpublished edits), and now it appears:
You could also just add a new empty SQLDatabase, and that would get the SQL Database node created in the left-hand pane, but that’s kinda my point – Azure is sometime a love/hate call, but whatever it is right now, it’ll probably have changed next time you look at it. It would be nice if the creation of the SQL Database from the Create External Table process added the node to the Workspace pane as well (if you already have some SQL Database, the new one will just appear in the list if you refresh it).
On balance, it’s still AMAZING that to CETAS, you don’t need to know all the ins and outs of CETAS, and you can carry on with your Old Skool database stuff without getting derailed. So it’s still a *love* from me.
Back soon(er)….