
‘Azure Synapse Link. You keep saying those words. I do not think it means what you think it means….’
OK, so, let me start by saying I *love* the idea of being able to query my Azure SQL Database from Synapse Analytics – who wouldn’t – but there are a couple of things to bear in mind when setting that up. If you don’t mind, I’ll step through the process so you can see what I mean…
Firstly, you set this up at the Azure SQL Database end first. I’m assuming here that you already have a database you want to link to Synapse Analytics, and that you already have an Azure Synapse workspace to query from ? Got that ? Great, let’s go…
Over in the Azure Portal, go find the database you want to link. Here I’ll be linking ‘MyDatabase’, but you’ll be linking ‘YourDatabase’ 🙂
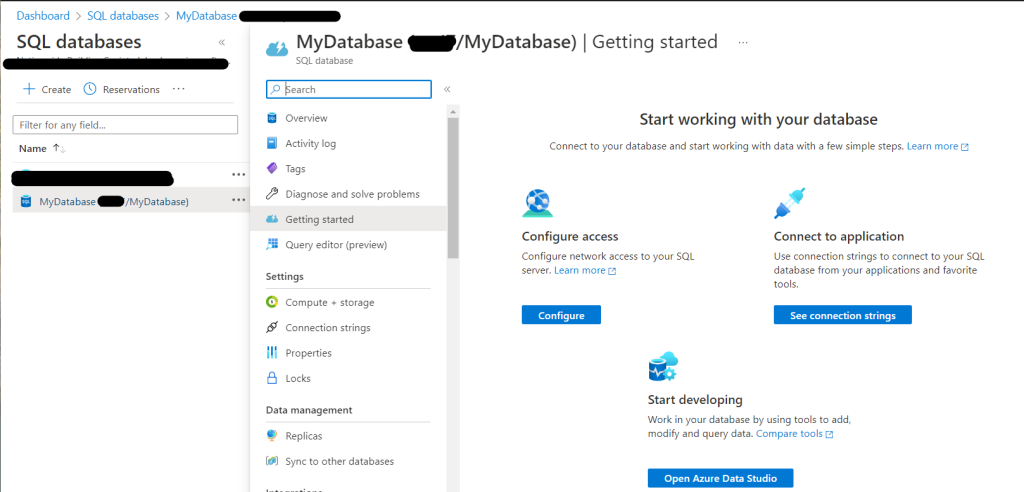
Scroll down the.. what is that called ? A picker ? A menu ?? Whatever, scroll down in until you find ‘Azure Synapse Link’:

Helpfully, you’re taken to a ‘Getting Started’ tab on a new page. Change to the ‘Enable Azure Synapse Link tab, and you’ll see this:
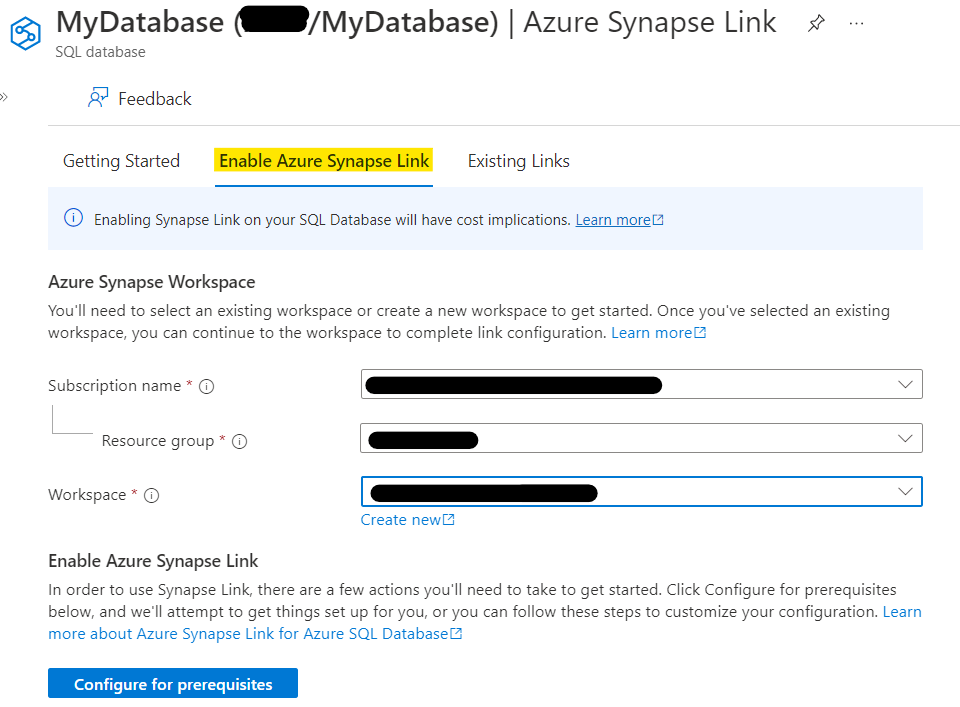
This is why you need a workspace to connect your database to 🙂 Fill in your details for the Subscription, Resource Group, and Workspace, stopping for a moment to read the notice at the top…

I’ll come back to that in a bit.
Setting up a Synapse Link has some pre-reqs that need to be in place on your SQL Database – Public Network Access should be enabled, Azure services need permission to access the database, and a system assigned managed identity needs to be enabled. I’m not going to go into that rn, but that’s what needs to be in place, so that’s what I’ll do.
Hitting the ‘Configure for prerequisites’ tells you what’s going to happen. In my case, all the pre-reqs are already met. If you don’t already meet them, there’ll be a red ‘x’ instead of a green tick, but when you hit ‘Continue’, the changes will be made. Notice also that these settings affect the instance that your SQL Database is on, not just the database – handy if you have a number of databases on the same server that you want to link to Synapse (hint: maybe do some pre-planning around this and make sure everything is in the right place)

The changes are then made and you get a confirmatory tick before hitting ‘Enable Link’:
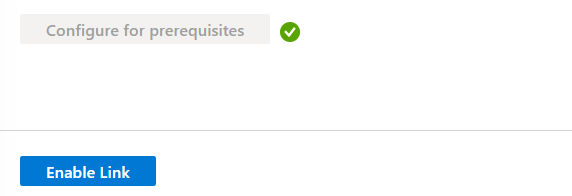
That doesn’t actually enable the link, in case you were wondering if that’s it. It connects you to your Azure Synapse workspace, starts Synapse Studio and presents you with some *more* choices to make in a ‘New Link Connection’. Side note: it doesn’t insert the name of the database you just enabled because reasons which will become apparent. Any existing databases already linked will appear in the drop-down. MyDatabase isn’t there, so I’m going to have to create a new one. No, not a new database, a new Source Linked Service.
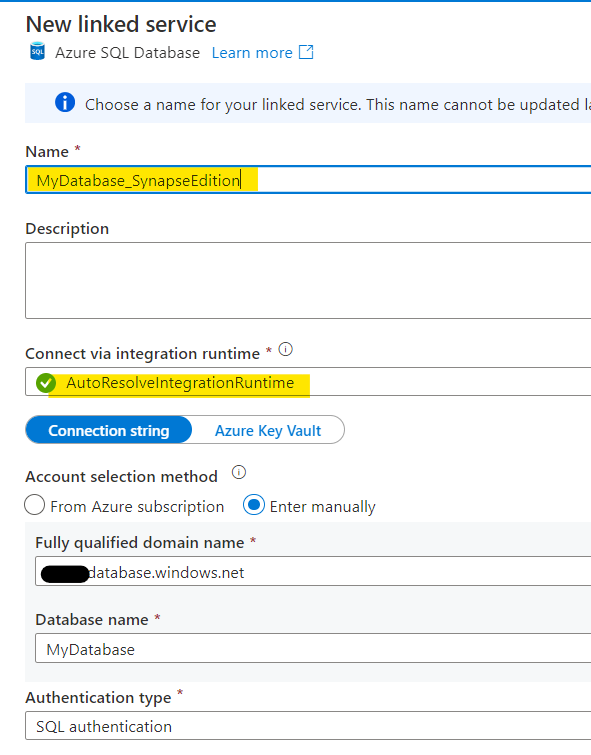
Name it something memorable, and note ‘Auto-resolve Integration Runtime’ – you can change this if you want and create a new (or existing) one if you prefer. I’m kinda basic, so the default is good for me.
Make sure the FQDN is the name of the instance that your database is on and the database yuo want to create the link to is correct (this should be pre-populated), sprinkle over some credentials to use to access the database and hit ‘Create’ when you’re happy.
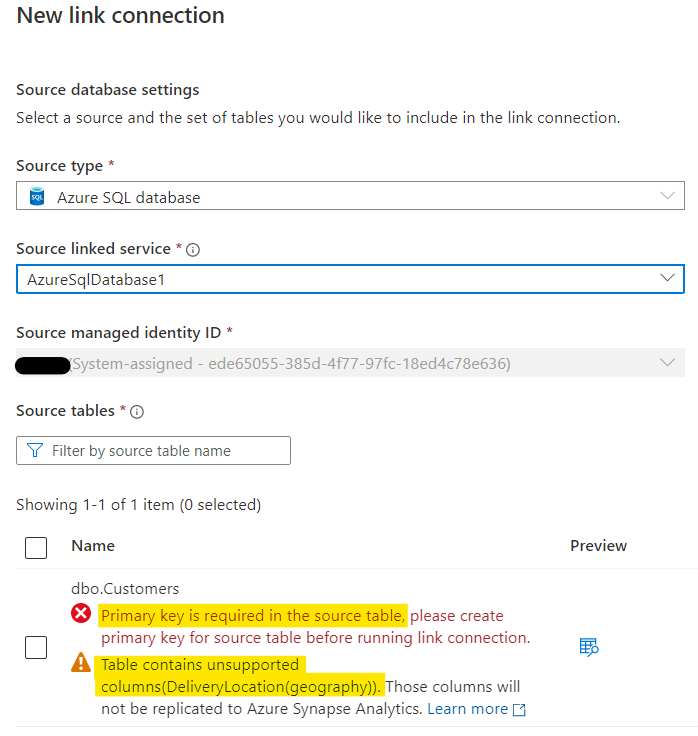
I have a table called ‘Customers’ in my database. It’s lonely because it’s the only table 😦 It also contains some datatypes that are not supported in Azure Synapse SQL Databases, but the link process is smart enough to tell me that it can ignore them for replication. It also points out that I don’t have a PRIMARY KEY on my table (for shame!), so won’t let me continue…
brb…..
OK, that’s fixed and I now have a PK on the table. All’s good. I’ll select the one solitary table in my database to link to Synapse and hit ‘Continue:
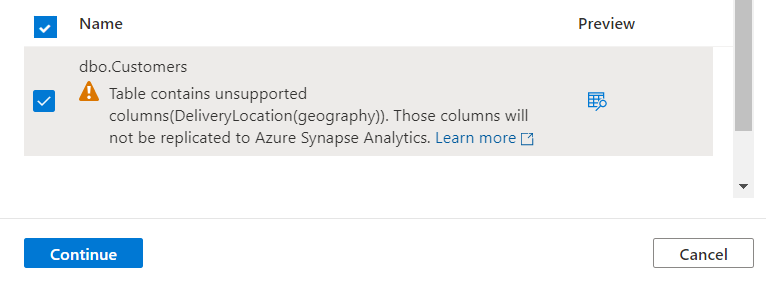
Right. So. Remember earlier on where it said that there would be cost implications in setting up Azure Synapse Link ? This is why:
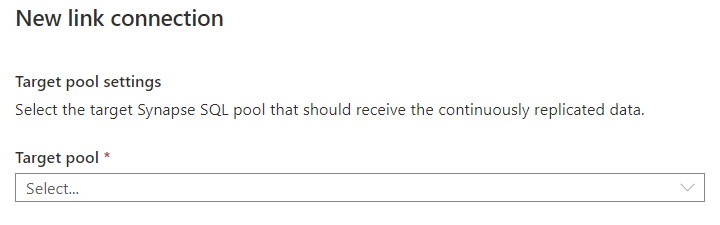
This needs a little explanation, I think.
We all know that Synapse has two types of SQL Polls – Serverless and Dedicated.
Serverless is largely free (OK, there’s some cost for storage of your data, but that’s about it, I think) whereas Dedicated means you have to stand up some compute explicitly, and *that* can come at a cost depending on the size of pool you need (Not going into that rn either).
Since Synapse Link is a way of using Synapse Studio on your Azure SQL Databases that stays up to date, you *need* something that’s always there to receive records that you put in it. Did you notice the words ‘not be replicated’ in the table selection ? It’s not a linked server as you might have used previously on-prem, it’s a replica (much like secondary replicas in an Availability Group scenario), and as such requires a Dedicated SQL Pool in the Synapse world.
Side note: Take a look at Managed Instance Link for Availabilty Groups – it’s very much like that, if not identical.
To save costs, you can pause a dedicated pool (but then you won’t receive updates into your replica, so…), but you still have to have one for Azure Synapse Link to work.
Anyway, back to the pretty pictures….
If you already have a dedicated SQL pool spun up, use that and hit ‘Continue’. If not, create one and then hit it 🙂
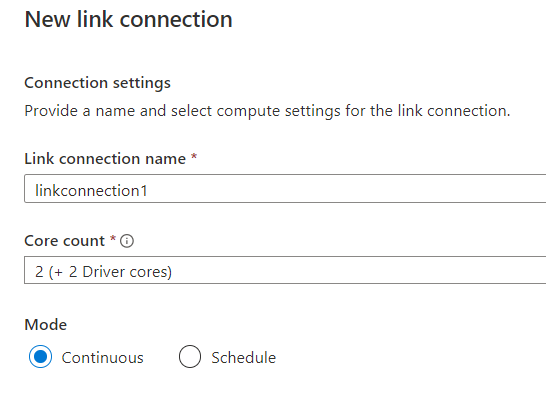
Everything needs a name, and you need to make some decisions about how many cores to use (really depends on velocity of records going into your Azure SQL Database), and whether you want to run this all the time or on a schedule. I’m just going to use ‘Continuous’ mode for now:
You then get some *more* decisions to make around Distribution and Structure Types. Again, I’m just using the defaults. Don’t feel like you have to, though…
Since it’s Azure Synapse now, you need to publish the link connection before you can start it:
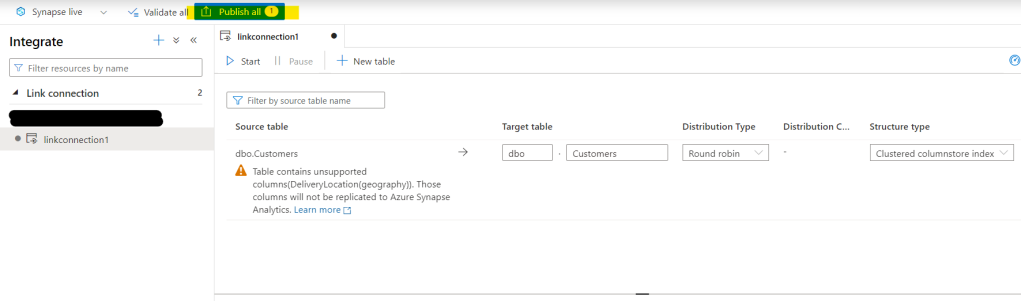
Once it’s published, you can start it. This might take a minute or two because your Dedicated SQL Pool is being spun up and connected to your source. Note also that you can pause the link here as well:
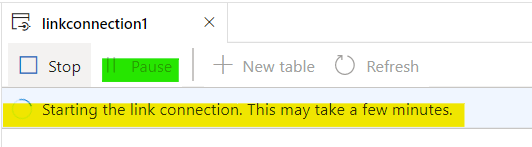
Indeed it does. Especially when I forgot that I paused the pool a while back to save costs ! D’oh ! But eventually, when the stars align, it starts:

You can add/remove data/tables/other stuff on your AZure SQL Database and that’ll be replicated to the .. err… replica in Azure Synapse, and you can do what you do in Synapse Studio 🙂
One last thing to point out, though. In Synapse Studio, you connect to the Dedicated Pool to query the data that’s now in Synapse. Don’t expect to see the details of the source database in there !
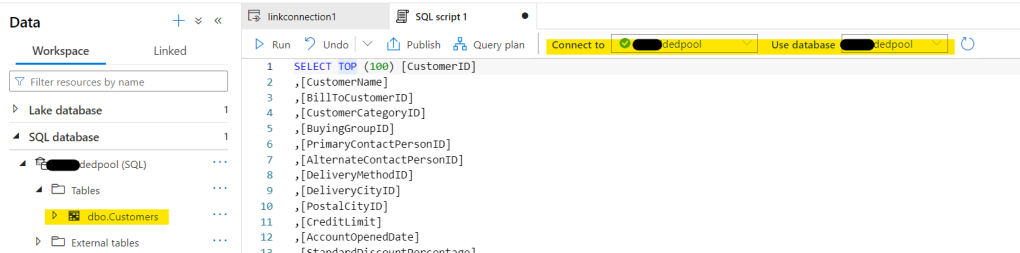
I guess in summary, Azure Synapse Link for Azure SQL Database isn’t the best name since it actually creates a replica of your source database and costs you money instead of just having a ‘special’ connection type. But I have to admit, it’s great tech whichever way you slice it.
Back soon…
