‘Fake it ’til you make it’
I love it when people provide you with something that lets you get started and is easy to implement. Azure Synapse Analytics Database Templates are (in my opinion) a bit short of the mark, though. They are only as good as what someone else thinks is good – for example, the Consumer Goods template has tables for Customer, Communication, and Warehouse, but none of the columns look like they’re for a physical address (and don’t get me started on the Transaction table).
That said, they still have value – if you’re just poking around and getting used to the environment they’re a great place to start. I’ve already talked about the Map Data tool to get your data into the templates (that’s an in-person only type thing – not something I think I can write down because it would be a loooooong read), but what if you didn’t have to ? What if there was a way of generating synthetic data and using that instead ?
Sidebar: Synthetic Data is one of the new hot topics. Generally, products get all excited about training Machine Learning models, and using them to generate fake data in a consistent manner. Opinion: This actually leans more into good RegEx patterns than ML, but let’s not go there right now.
Helpfully, there is a resource in GitHub that will generate data in your chosen empty template 🙂 It doesn’t even need to know the schema because it works that out itself – it just needs to know the name of your Lake database !
Oh, and it also needs you to set up some stuff and assumes that you know how to do something that’s not immediately apparent when you has set up the stuff. So close !!
The data is (are?) generated by a Python notebook that’s provided, but require you to set up a Spark Pool to run the notebook, and also make sure that a specific Python library is available at runtime.
OK, let’s take a look at the mechanics…
Here’s a bright, shiny, empty Consumer Goods lake database that was created from the Consumer Goods template (duh):
As mentioned, we’re going to need a Spark Pool to run the Notebook. It doesn’t need to be massive, but if it’s too small (not enough cores or RAM) generating the synthetic data will take yonks, and Spark Pools are billed by the hour…
Head over to the ‘Manage’ icon, then ‘Spark Pools’ and select ‘+ New’:
The configuration recommended is in the GitHub documentation, so we’ll just use that.
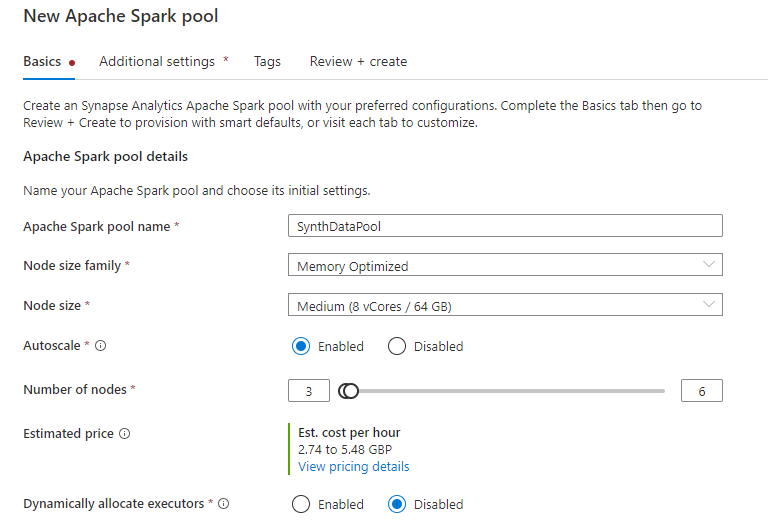
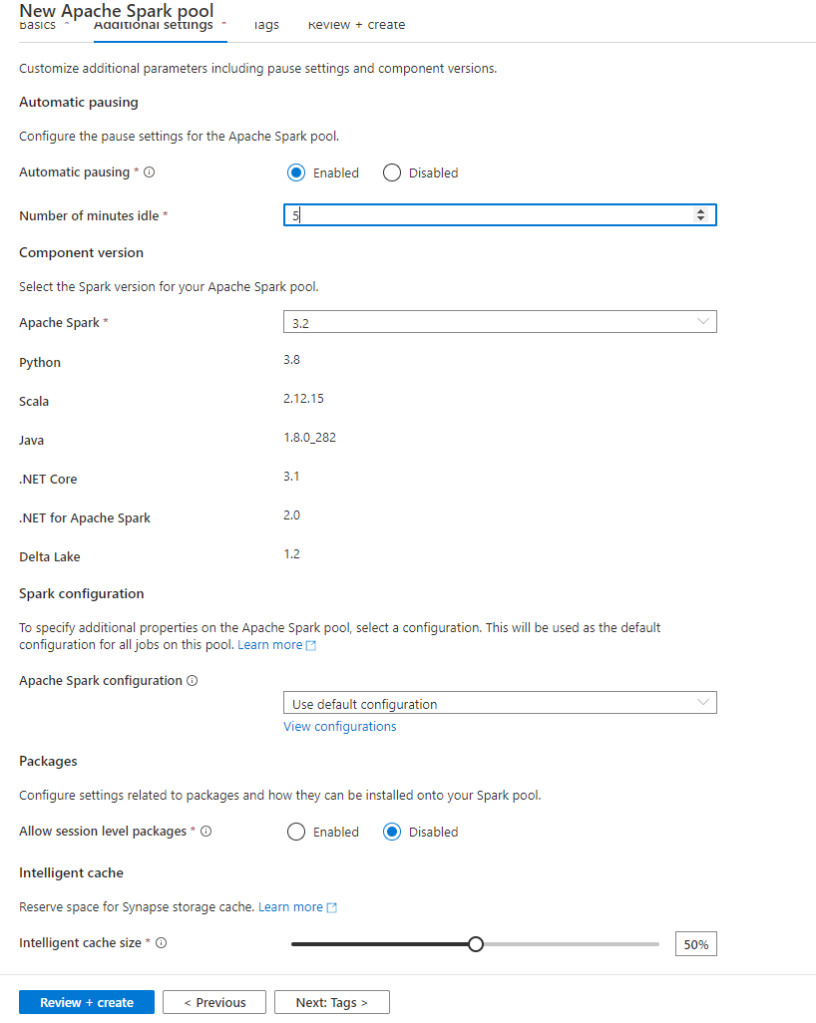
Go right ahead and create the Spark Pool.
We’ve read the documentation that says we need “A Spark pool with the python library ‘Faker’ installed (simplest method is to have a requirements.txt with a line of text with the library name “faker” loaded in the cluster configuration). ” We have just created the Spark Pool. The simplest method would actually be to explain how you do that in the marksdown. Here goes…
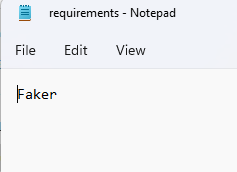
Create a text document called ‘requirements.txt’ on your device’s filesystem. Open it, and type the word ‘Faker’ on the first line, with no leading or trailing spaces or other whitespace that migh mess you up (it’s not YAML, but good practice is good practice, right ?). Save that file and remember where you saved it. <– I can’t always remember where I saved the document I just created 🙂
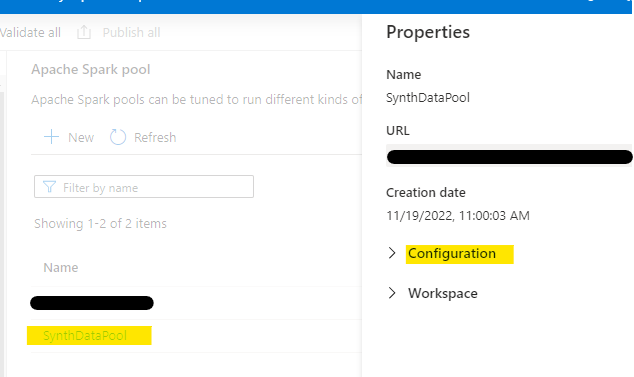
We now come across another one of those special moments in Azure where things aren’t where you’d expect them to be. What we want to do now is configure our Spark Pool to always load the Faker library on start-up, so you’d think that would be in the configuration blade…
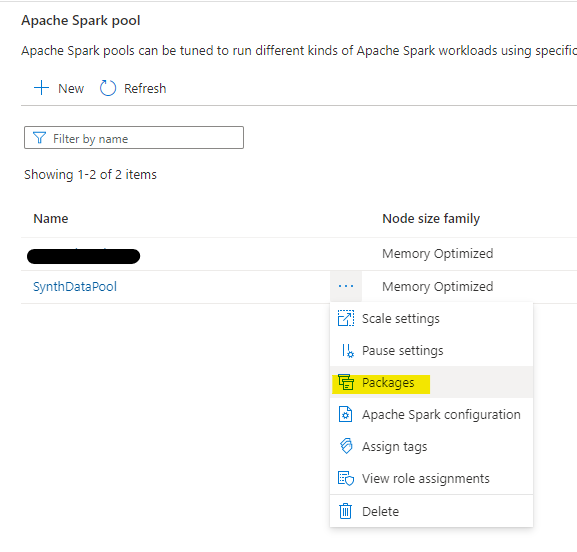
It’s not. It’s here:
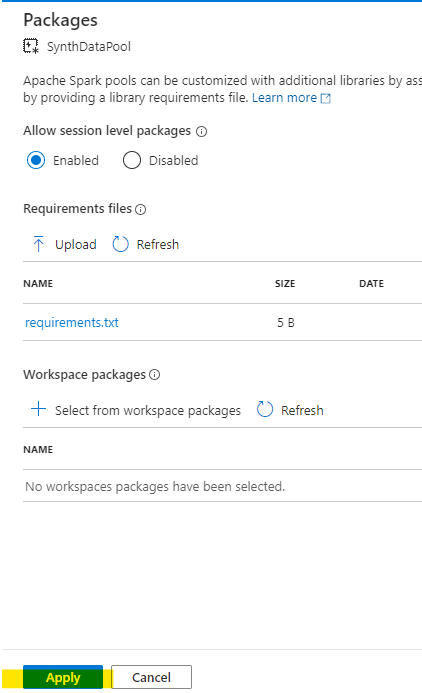
We need to enable session packages in the Spark Pool (they’re disabled by default) and tell it what our requirements are for default packages to apply at startup by uploading the requirements.txt file we created earlier:
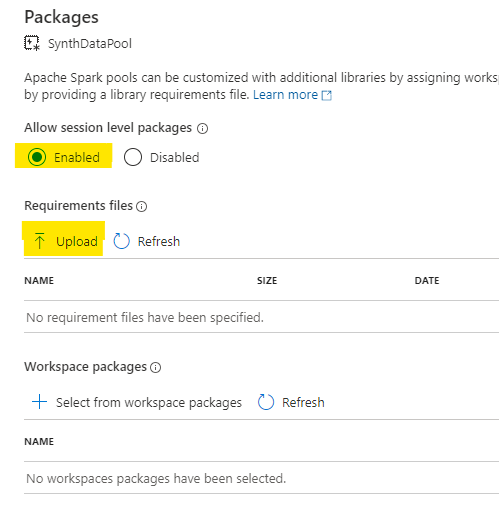
When the file is upoaded, hit ‘Apply’ and possiby put the kettle on. It can take a few minutes to apply. My advice is to keep the Notifications blade open and do *nothing* until you see the ‘success’ message 🙂
So now we have a Spark Pool with Faker pre-initialised / loaded / installed / whatever the term is. Next step is to copy the notebook contents from the GitHub resource and paste them into a new notebook in Synapse Studio.
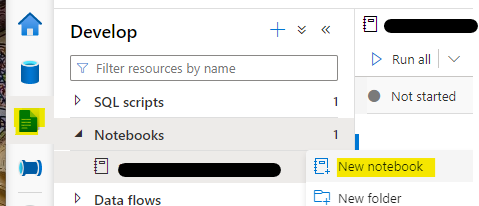
Once you’ve got the notebook created (I called mine ‘Synthetic Data Generator’), attach it to your Spark Pool, and change the database name in the first code cell to the name of your shiny new empty templated Lake database:

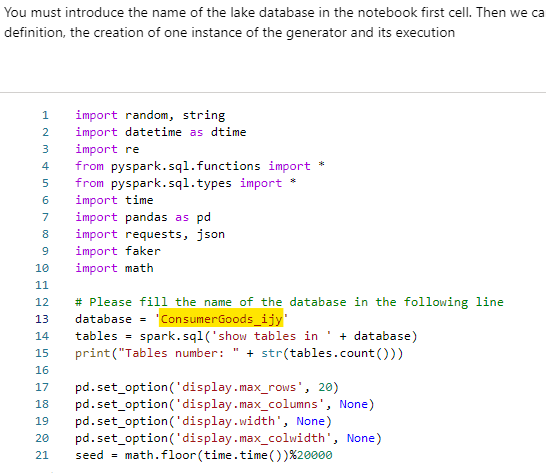
When we run the first code cell, it will detect the schema in your database (tables, columns, datatypes, etc) and use those in the next cell to generate the data.
Note: These next bits can take quite some time. It’ll take a few minutes to spin up the Spark Pool, and generating the data takes a while as well.

Yeah, OK. That’s just the first code cell. Feel free to run the second, but be prepared to wait *even* longer… at least we don’t have to wait for the pool to start up…
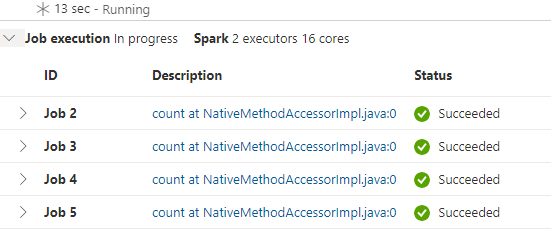
When that’s completed (my, that’s a lot of jobs!), we have successfully generated quite a few rows in each table. It’s not 100% clear how much data can be faked using this method, but a few hundred thousand rows seems like a reasonable data set.
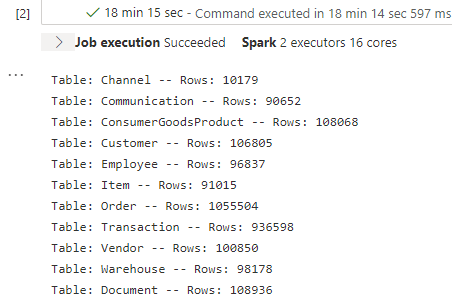
Going back in the the database, we can see that there’s data there, and that there is *some* referential integrity preserved through relationships in the schema, but since there are no foreign keys in the schema, they’re not enforced in the generated dataset. For example, there are no customers that do not also have a transaction recorded (which you’d expect from a store)…
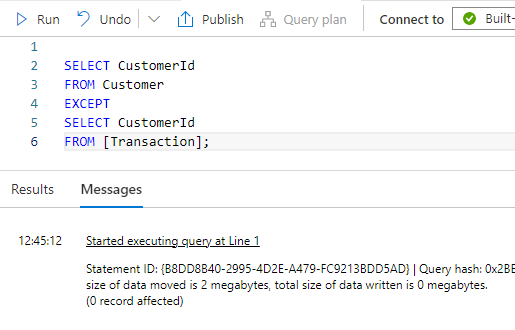
… but there are transactions that have customer ids that are not in the customer table…
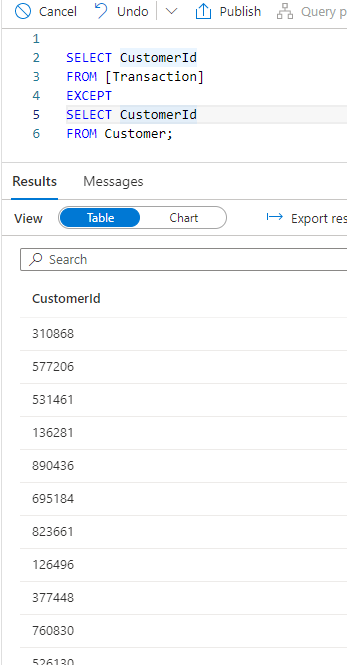
That’s probably more to do with the fact that the schemas in the templates do not enforce referential integrity, and that’s probably due to the fact that the data is stored in block blobs in your DataLake Gen 2 storage, but I guess you already knew that… 🙂
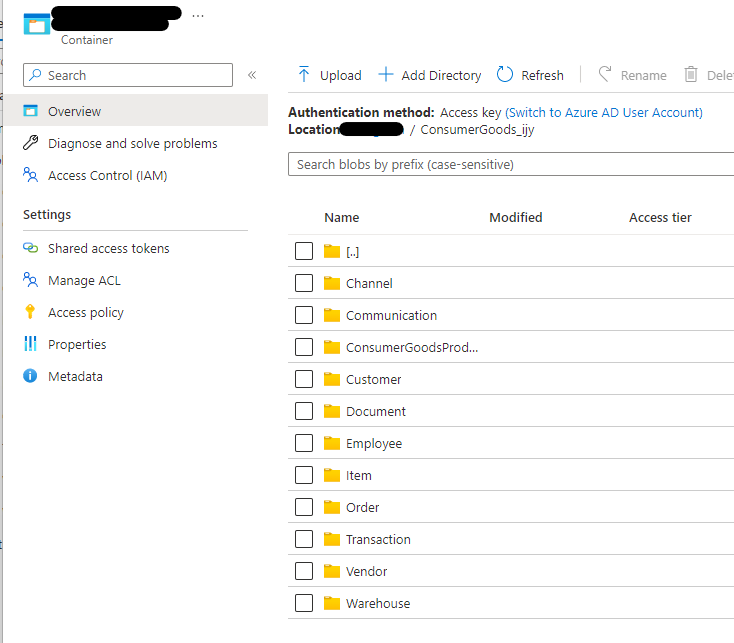
So that’s just a quick look at creating synthetic data in Azure Synapse Analytics Database Templates.
Hope that’s useful ?
Back soon….
