There’s a lot of focus at the moment on GDPR, the General Data Protection Regulations that come into force in Europe on May 25
th 2018 (for further info if this is news to you, see
here)
SQL Server Management Studio (SSMS) now has an add-in to classify your data (
TechNet blog), but I thought this merited further digging to see how it’s implemented under the covers, and where the data for the classification is stored.
So, it appears that the data classification is held in the database Extended Properties. Extended Properties were introduced way back in SQL 2005, I think, but it wasn’t until the SQL2008 version of SSMS was released that they could be viewed as part of a database.
Like any good DBA who’s hacked around in SSMS before, you’ve probably wondered what goes on under the covers, and the best way to do that is to run a Profiler Trace while you fiddle about in the SSMS UI 🙂
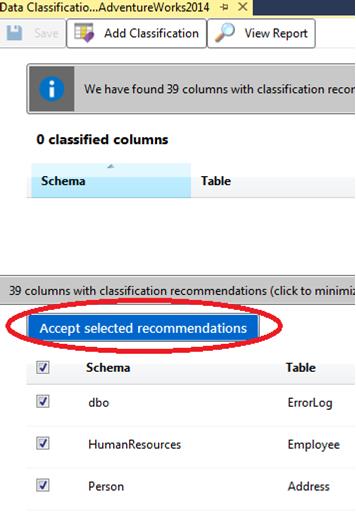
Let’s add some classifications to our database – using good ol’ AdventureWorks:
This opens a new tab in SSMS, with some recommendations as to what the likely classifications might be. Note: no data has been written to the database properties yet – that only happens when you save the classifications.
Creating this table runs some hard-coded T/SQL to get stuff from INFORMATION_SCHEMA.COLUMNS and build the ‘best guesses’ from the column names and datatypes. Also, note that the ‘matching’ of likely columns to types is done in several languages (I’ve omitted some for clarity here):
DECLARE @Dictionary TABLE
(
pattern NVARCHAR(128),
info_type NVARCHAR(128),
sensitivity_label NVARCHAR(128),
can_be_numeric BIT
)
INSERT INTO @Dictionary (pattern, info_type, sensitivity_label, can_be_numeric)
VALUES
(\’%username%\’ ,\’Credentials\’ , \’Confidential\’ ,1),
(\’%pwd%\’ ,\’Credentials\’ , \’Confidential\’ ,1),
(\’%password%\’ ,\’Credentials\’ , \’Confidential\’ ,1),
(\’%email%\’ ,\’Contact Info\’ , \’Confidential – GDPR\’ ,0),
(\’%e-mail%\’ ,\’Contact Info\’ , \’Confidential – GDPR\’ ,0),
(\’%last%name%\’ ,\’Name\’ , \’Confidential – GDPR\’ ,0),
(\’%first%name%\’ ,\’Name\’ , \’Confidential – GDPR\’ ,0),
(\’%surname%\’ ,\’Name\’ , \’Confidential – GDPR\’ ,0),
(\’%mainden%name%\’ ,\’Name\’ , \’Confidential – GDPR\’ ,0),
(\’%addr%\’ ,\’Contact Info\’ , \’Confidential – GDPR\’ ,0),
(\’%número%de%cartao%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%numero%de%cartão%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%numero%de%tarjeta%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%numero%della%carta%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%numero%di%carta%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%numero%di%scheda%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%numero%do%cartao%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%numero%do%cartão%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%numéro%de%carte%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%nº%carta%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%veiligheidsaantal%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%veiligheidscode%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%veiligheidsnummer%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%verfalldatum%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%ablauf%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%data%de%expiracao%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%data%de%expiração%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%data%del%exp%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%data%di%exp%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%data%di%scadenza%\’ ,\’Credit Card\’ , \’Confidential\’ ,1),
(\’%Ausweis%\’ ,\’National ID\’ , \’Confidential – GDPR\’ ,1),
(\’%Identifikation%\’ ,\’National ID\’ , \’Confidential – GDPR\’ ,1),
(\’%patente%di%guida%\’ ,\’National ID\’ , \’Confidential – GDPR\’ ,1)
DECLARE @InfoTypeRanking TABLE
(
info_type NVARCHAR(128),
ranking INT
)
INSERT INTO @InfoTypeRanking (info_type, ranking)
VALUES
(\’Banking\’, 800),
(\’Contact Info\’, 200),
(\’Credentials\’, 300),
(\’Credit Card\’, 700),
(\’Date Of Birth\’, 1100),
(\’Financial\’, 900),
(\’Health\’, 1000),
(\’Name\’, 400),
(\’National ID\’, 500),
(\’Networking\’, 100),
(\’SSN\’, 600),
(\’Other\’, 1200)
DECLARE @ClassifcationResults TABLE
(
schema_name NVARCHAR(128),
table_name NVARCHAR(128),
column_name NVARCHAR(128),
info_type NVARCHAR(128),
sensitivity_label NVARCHAR(128),
ranking INT,
can_be_numeric BIT
)
INSERT INTO @ClassifcationResults
SELECT DISTINCT S.NAME AS schema_name,
T.NAME AS table_name,
C.NAME AS column_name,
D.info_type,
D.sensitivity_label,
R.ranking,
D.can_be_numeric
FROM sys.schemas S
INNER JOIN sys.tables T
ON S.schema_id = T.schema_id
INNER JOIN sys.columns C
ON T.object_id = C.object_id
INNER JOIN sys.types TP
ON C.system_type_id = TP.system_type_id
LEFT OUTER JOIN @Dictionary D
ON (D.pattern NOT LIKE \’%[%]%\’ AND LOWER(C.name) = LOWER(D.pattern) COLLATE DATABASE_DEFAULT) OR
(D.pattern LIKE \’%[%]%\’ AND LOWER(C.name) LIKE LOWER(D.pattern) COLLATE DATABASE_DEFAULT)
LEFT OUTER JOIN @infoTypeRanking R
ON (R.info_type = D.info_type)
WHERE (D.info_type IS NOT NULL ) AND
NOT (D.can_be_numeric = 0 AND TP.name IN (\’bigint\’,\’bit\’,\’decimal\’,\’float\’,\’int\’,\’money\’,\’numeric\’,\’smallint\’,\’smallmoney\’,\’tinyint\’))
SELECT DISTINCT
CR.schema_name AS schema_name,
CR.table_name AS table_name,
CR.column_name AS column_name,
CR.info_type AS information_type_name,
CR.sensitivity_label AS sensitivity_label_name
FROM @ClassifcationResults CR
INNER JOIN
(
SELECT
schema_name,
table_name,
column_name,
MIN(ranking) AS min_ranking
FROM
@ClassifcationResults
GROUP BY
schema_name,
table_name,
column_name
) MR
ON CR.schema_name = MR.schema_name
AND CR.table_name = MR.table_name
AND CR.column_name = MR.column_name
AND CR.Ranking = MR.min_ranking
ORDER BY schema_name, table_name, column_name
BTW, if anyone from Microsoft is reading this, you might want to correct the typo for “%mainden%name%”…
OK, so now we have our SSMS tab full of classification suggestion goodness. Let’s just accept the recommendations (and why wouldn’t you), and save the definitions back to SQL Server:
In the Profiler trace that you should be running (!), you’ll see what SQLServer does when you save the classifications. It calls ‘sp_addextendedproperty’ with parameters for each of the items that are required to be saved. It actually adds 4 properties for each one (type, type_id, label, and label_id), but you get the idea…
exec sp_addextendedproperty @name=N\’sys_information_type_name\’,@level0type=N\’schema\’,@level0name=N\’Sales\’,@level1type=N\’table\’,@level1name=N\’SalesTaxRate\’,@level2type=N\’column\’,@level2name=N\’TaxRate\’,@value=N\’Financial\’
go
exec sp_addextendedproperty @name=N\’sys_information_type_id\’,@level0type=N\’schema\’,@level0name=N\’Sales\’,@level1type=N\’table\’,@level1name=N\’SalesTaxRate\’,@level2type=N\’column\’,@level2name=N\’TaxRate\’,@value=N\’C44193E1-0E58-4B2A-9001-F7D6E7BC1373\’
go
exec sp_addextendedproperty @name=N\’sys_sensitivity_label_name\’,@level0type=N\’schema\’,@level0name=N\’Sales\’,@level1type=N\’table\’,@level1name=N\’SalesTaxRate\’,@level2type=N\’column\’,@level2name=N\’TaxRate\’,@value=N\’Confidential\’
go
exec sp_addextendedproperty @name=N\’sys_sensitivity_label_id\’,@level0type=N\’schema\’,@level0name=N\’Sales\’,@level1type=N\’table\’,@level1name=N\’SalesTaxRate\’,@level2type=N\’column\’,@level2name=N\’TaxRate\’,@value=N\’331F0B13-76B5-2F1B-A77B-DEF5A73C73C2\’
go
This was just to classify one column, Tax Rate, as type ‘Financial’ and label ‘Confidential’.
This information is saved as a database-scoped extended property, so the classifications are completely portable on backup/restore if you were to move the database for some reason. #ftw
Sadly, these are *not* available in the normal database extended properties UI, but you could query them directly if you wanted to extract them programmatically using the static T/SQL gleaned from the trace:
I hope that’s shown you where the classification data is held. It’s a simple (!) job to add the server name and database name to the query so you could use it to provide information on all your classifications across all your databases and servers, but I’ll leave that fun to you !
Back soon !!
When I was a slip of a lad, my dad had some recordings (legitimate, I assure you) by a comedian/folk singer/now Radio 2 presenter called Mike Harding.
Whilst the subject matter was occasionally ribald for a 10-year-old, some of the songs really struck a chord, and I now remember them still.
One such song was called \”Some things that the grown-ups just don\’t tell you\” in which a child\’s inquiring mind asks such searching questions as \”If you eat food all different colours, why does it all come out brown?\” and \”If you undo your belly-button, does your bum really fall off?\”
With that in mind (and very much earwormed myself with that one), this leads me on continually discover things that should be easy to answer but turn out give the bum\’s rush when searching the internet.
The question I asked myself was:
\”When using SQL 2014 In Memory Session State, which elements of the application stack require .Net 4 or above?\”
Quite aside from the arguments against storing session state in the least performant manner in the first place, my google-fu deserted me for quite some time – definitive answers are hard to come by these days, it’s all ‘alternative facts’.
As a DBA, I understand that at the database layer, a recent version of .Net is required to handle the creation of natively compiled stored procedures that the ASPStateInMemory database schema requires, but does that necessarily apply further up the application stack ?
Logic would dictate not (in my view) – it\’s simply a Remote Procedure Call from the application or web service, and should therefore be agnostic as to the underlying technology. Shouldn\’t it ?
In a perfect world, yes, it very much should. But as we all know from recent history, the world is very much far from perfect.
ASPStateInMemory requires a new .Net provider. That provider is in .Net4, and is compiled using the CLR for that version.
You can\’t point an existing session state connection at the InMemory version without that.
So, if you\’re applications or services are compiled in .net 3.51, they\’ll be using the wrong version of the session state provider, written for CLR 2.0.
THIS MEANS:
If you\’ve not been diligent in keeping pace with the .net Framework versions in your development, or have existing legacy applications that would benefit from moving to InMemory session state, you can’t use ASPStateInMemory without re-writing them for the later version of the Framework.
The answer took me a while to find and then understand, but it appears the answer is:
\”All of your application stack.\”
…and *that* might be expensive…
Oh dear. Back to the drawing board then. I think I left some indexes over there… I\’ll just see how fragmented they are….
Back soon !
It\’s not just the data that\’s big
Big Data ! How cool is that ! Imagine all the things that your big data can tell you !
All you have to do it implement it, right ? How hard can that be ??
Answer: It’s VERY hard indeed for such a simple concept.
But why is it so hard ?
Largely, it’s because of the choices you’ll have to make, the platforms you deliver on, and the suppliers you’ll have to deal with.
Sure, there are lots of big data solutions, just like there are lots of big data consultancies, but ALL of them come at a cost, no matter how ‘free’ they are.
Just by way of further reading, I recommend this:
http://dataconomy.com/understanding-big-data-ecosystem/
It’s a short article, detailing the general areas you’ll need to be considering, such as Infrastructure, Analytics and Applications, and is well worth a look.
The main thing you might realise while reading it is the sheer scale of the big data business. A few short years ago, you had your RDBMS of choice (SQL Server, DB2, Oracle,…), some flat files out of your legacy system, and some spreadsheets that Dave in Accounts was using to track how many toner cartridges he needed to order.
Now you got everything. Literally everything. And some other stuff besides that you didn’t even know existed.
Picking the right platform from that lot seems like a Herculean task. Indeed, maybe there is no ‘right’ platform ? And if not, how many platforms are too many? Then, it’s not just about the platform your data is currently stored in, it’s also about integrating those data sources to really deliver valuable insight to your business in simple and flexible way.
Perhaps the question we need to be asking is ‘What does our data look like, and what does the business need it to look like?’.
From that question, you can start to see where you want to be. Getting there is still going to be tough, but at least you’ll have an idea of what success might be.
And perhaps, if you can have some fun along the way, that wouldn’t be a bad thing either J
Back soon…
SQL Trace Flag 3004 and BACKUP database
Quick one today � Someone asked me if there\’s a starting equivalent of this message:
04/23/2014 11:46:53,Backup,Unknown,Database backed up. Database: foo creation date(time): 2013/11/07(12:19:59) pages dumped: 363 first LSN: 44:888:37 last LSN: 44:928:1 number of dump devices: 1 device information: (FILE=1 TYPE=DISK: {\’C:\\Temp\\foo.bak\’}). This is an informational message only. No user action is required.
You know, so we can track when a database backup starts, and what it\’s doing while backing up… and stuff…
There\’s plenty on trace flag 3004 for RESTORE operations from a backup file so you can identify which areas of your restore operations are taking a while, such as zeroing out and creating devices, etc, but not much on the BACKUP side of things. All I could see was that the trace flag would output detail to the error log if invoked thusly:
DBCC TRACEON (3004,3605,-1)
Take a look at http://blogs.msdn.com/b/psssql/archive/2008/01/23/how-it-works-what-is-restore-backup-doing.aspx for further reading on that. And there\’s plenty others as well, like http://jamessql.blogspot.co.uk/2013/07/trace-flag-for-backup-and-restore.html
I was a bit stumped for the BACKUP bit, so I asked the #sqlhelp tag on twitter if there was another flag for backup. Thanks to @SQLKiwi, turns out it\’s the same one.
So, with that trace flag turned on as above, the output you get in the SQL error log is far more detailed (I\’ve turned the list so it reads in the correct event order):
Date Source Severity Message
04/23/2014 11:47:51 spid52 Unknown BackupDatabase: Database foo
04/23/2014 11:47:51 spid52 Unknown Backup: Media open
04/23/2014 11:47:51 spid52 Unknown Backup: Media ready to backup
04/23/2014 11:47:51 spid52 Unknown Backup: Clearing differential bitmaps
04/23/2014 11:47:51 spid52 Unknown Backup: Bitmaps cleared
04/23/2014 11:47:51 spid52 Unknown BackupDatabase: Checkpoint done
04/23/2014 11:47:51 spid52 Unknown Backup: Scanning allocation bitmaps
04/23/2014 11:47:51 spid52 Unknown Backup: Done with allocation bitmaps
04/23/2014 11:47:51 spid52 Unknown BackupDatabase: Work estimates done
04/23/2014 11:47:51 spid52 Unknown Backup: Leading metadata section done
04/23/2014 11:47:51 spid52 Unknown Backup:Copying data
04/23/2014 11:47:51 spid52 Unknown Backup: DBReaderCount = 1
04/23/2014 11:47:51 spid52 Unknown Started file C:\\Program Files\\Microsoft SQL Server\\MSSQL11.TEST1\\MSSQL\\DATA\\foo.mdf
04/23/2014 11:47:51 spid52 Unknown Completed file C:\\Program Files\\Microsoft SQL Server\\MSSQL11.TEST1\\MSSQL\\DATA\\foo.mdf
04/23/2014 11:47:51 spid52 Unknown BackupDatabase: Database files done
04/23/2014 11:47:51 spid52 Unknown �正灵��慢�退%s : Log files done : Log files done
04/23/2014 11:47:51 spid52 Unknown Backup: Trailing config done
04/23/2014 11:47:51 spid52 Unknown Backup: MBC done
04/23/2014 11:47:51 spid52 Unknown BackupDatabase: Writing history records
04/23/2014 11:47:51 Backup Unknown Database backed up. Database: foo creation date(time): 2013/11/07(12:19:59) pages dumped: 362 first LSN: 44:1040:37 last LSN: 44:1072:1 number of dump devices: 1 device information: (FILE=1 TYPE=DISK: {\’C:\\ Temp\\foo.bak\’}). This is an informational message only. No user action is required.
04/23/2014 11:47:51 spid52 Unknown Writing backup history records
04/23/2014 11:47:51 spid52 Unknown BackupDatabase: Finished
With this detail, it\’s relatively simple to alert on when a BACKUP event starts, or any part of that backup event, and you could also use it for identifying which parts of your database backup are taking a long time.
Just though I should write something up for BACKUP as well as RESTORE…
Back soon….